Novel method for compressing tree ensembles at ICML 2025
-
08/08/2025
-
NewsNews

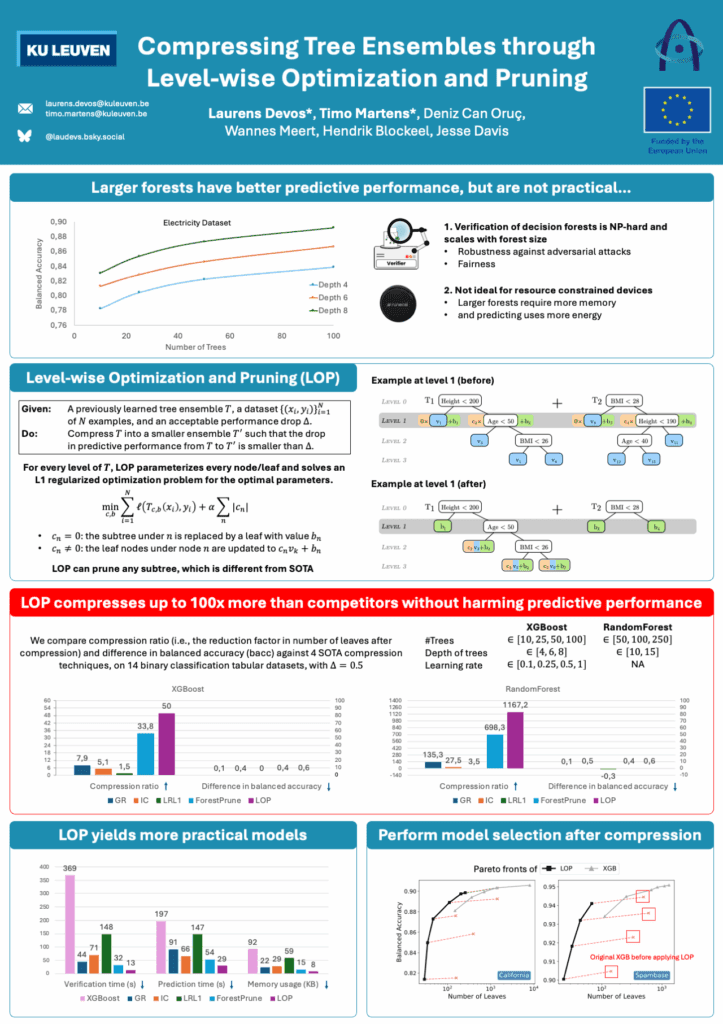
Model compression is a critical topic for making machine learning more efficient and trustworthy. The poster that was presented introduced LOP (Level-wise Optimization and Pruning), a novel method designed to dramatically reduce the size of decision tree ensembles while maintaining comparable predictive performance.
Tree ensembles are widely used in practice due to their accuracy, low training cost, and robustness on tabular data. However, their growing size poses challenges when used in applications that require:
- Verification of robustness or fairness (as verification complexity increases with model size)
- Deployment on battery-powered devices, where smaller models reduce energy consumption and extend battery life.
LOP addresses these issues head-on by compressing existing forests through a level-by-level pruning strategy.
At each tree level, LOP optimizes which subtrees can be safely removed and updates remaining leaf values to minimize accuracy loss. Compared to prior methods, LOP achieves compression ratios up to 1000x, with minimal loss in predictive power.
Notably, the models compressed with LOP:
- Are more efficient and lightweight — ideal for embedded applications
- Are easier to verify — making them more suitable for deployment in safety-critical or fairness-sensitive environments
- Maintain or even improve robustness under adversarial conditions
This work highlights how TUPLES research contributes to building trustworthy, high-performance AI that is also resource-aware and verifiable.
Congratulations to the team at KU Leuven for this contribution!
Explore the complete presentation here